
Introduction
If you’ve invested in a third-party LLM, you can use it to power the Generative AI features in your Conversational Cloud solution. This lets you align the solution with your brand’s overall LLM strategy.
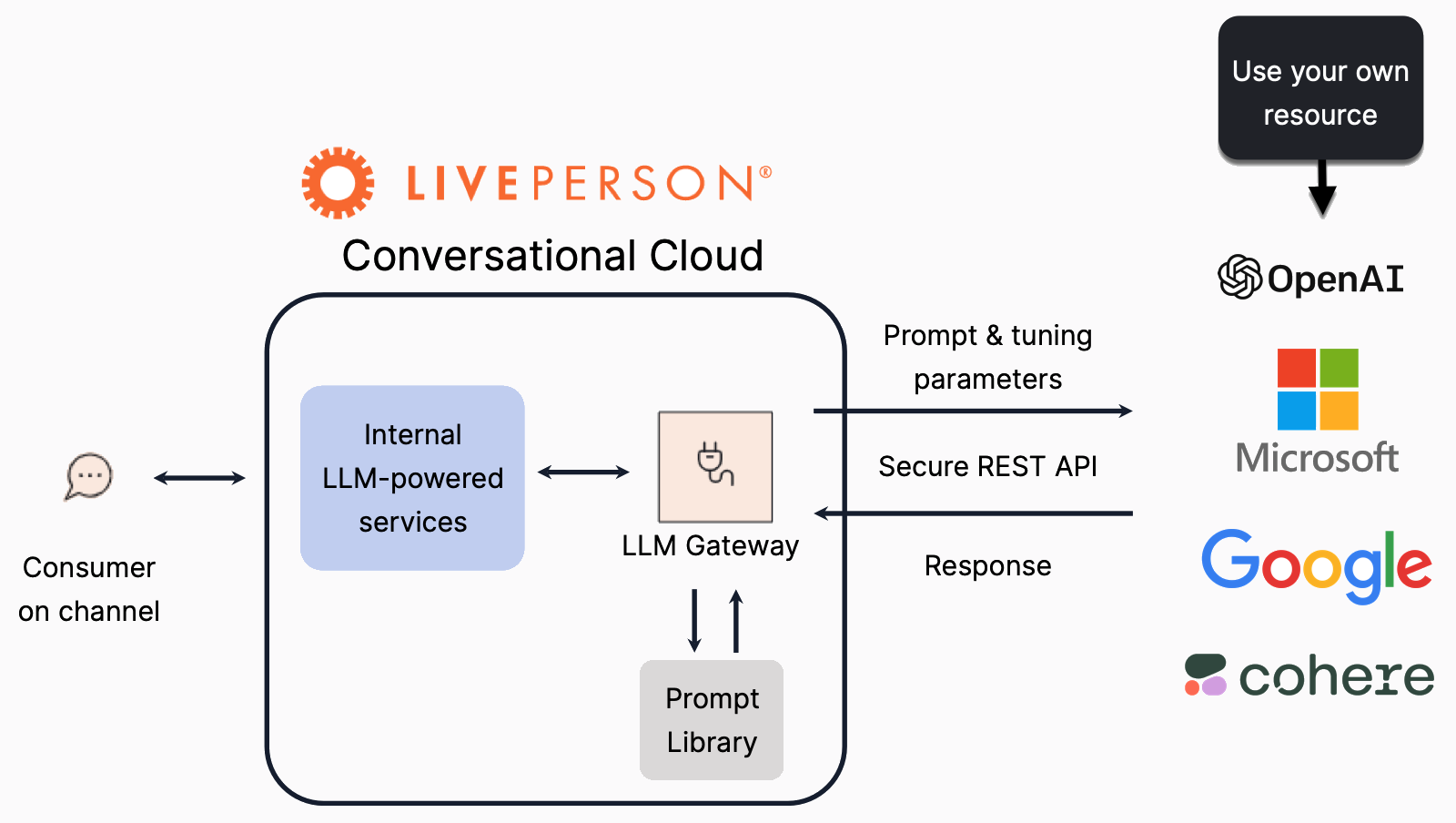
Key benefits
- Enhanced customization: Use a model that’s fine-tuned by you using your brand’s data.
- Security and compliance: Configure your LLM per your security and compliance needs.
- Increased efficiency and optimized performance: Establish your own SLAs and ensure consistent performance that’s tailored to your needs.
- Cost transparency: Gain full clarity on the model’s traffic and cost.
- Flexibility: Bringing your own LLM doesn't mean you have to use it everywhere in your Conversational Cloud solution. You can use your own in-house LLM for some Conversational AI use cases, and use the ones available via LivePerson for other use cases.
Getting started
To get started, fill out this form and schedule a meeting with us.
In the meeting, we'll discuss your desired solution with you.
Later, when you onboard your LLM, you’ll need to provide:
- Your Conversational Cloud account ID
- The path to the endpoint
- The API key
Load balancing
LivePerson’s LLM Gateway can perform client-side load balancing across resources. If you provide us with multiple endpoints, also provide your desired weight value for each endpoint.
The weight value is just an assigned number. Resources with a greater weight will be called more. So, for example, if you assign weight value "1" to resource A and weight value "2" to resource B, then in every cycle, resource A will be called 1 time, and resource B will be called 2 times. You might want to assign greater weight to freer resources.
Best practices
-
Setup and onboarding: When you set up your in-house OpenAI GPT 3.5 Turbo instance in Microsoft Azure:
- Enable IP whitelisting to block unexpected external access, and whitelist Liveperson’s IP ranges as per this article.
- Create a dedicated API key to share with Liveperson; this API key should be used exclusively by Liveperson’s LLM Gateway.
- Share the API key in any format you desire. We recommend you do so in a manner that limits access to only those who are necessary, e.g., your LivePerson account representative.
- Load balancing: To optimize performance and scalability, configure multiple endpoints for the model and deploy them across multiple regions. LivePerson’s LLM Gateway can perform load balancing, as described above.
- Content logging: Configure content logging for your in-house LLM as you require (to facilitate model training, fine tuning, etc.). Note that LivePerson disables content logging as a best practice. Learn more about data, privacy, and security.