
On this page, we’ll introduce the different concepts that are relevant for the LivePerson Functions platform. To effectively leverage the platform, you should familiarize yourself with these underpinnings. This will help you build robust solutions and avoid implementing use cases that are not feasible within our architectural constraints.
Concurrency
Concurrency describes how we handle and process multiple requests happening at the same time. This is a crucial aspect of Function-as-a-Service (FaaS) offerings.
In Functions V2, we handle one request per instance. This behavior differs from our previous version, where requests were batched. Because requests are isolated to their own instances, you cannot rely on a "local" state. For example, changing a global variable in one request will not be visible to other running instances.
The platform spawns multiple instances based on the overall traffic received. However, there are limits:
- Scaling: If your function takes a long time to execute and receives a high volume of parallel requests, you might breach the maximum allowed instances.
-
Throttling: If this limit is breached, you will observe
429 Too Many Requestserrors.
Because each instance handles exactly one request at a time, your function's execution time directly determines its maximum throughput. See Limitations for details.
The default limits work well for regular flows. However, if your specific use case requires high concurrency for long-running functions, you may need to ask LivePerson to adjust the maximum allowed instances.
Avoid writing code that relies on local state tracking, as function instances do not share state.
Cold start
A "cold start" refers to the time cost incurred when we spawn a new function instance to handle an incoming request.
Instances that do not receive traffic for a certain period — typically a few minutes — will eventually shut down to save resources. When a new request arrives after this shutdown, the platform must spin up a new instance. This process generally produces a delay of 2s — 5s, depending on the allocated CPU.
You should be aware of this limitation when designing latency-sensitive flows.
- Keep it warm: If you cannot afford the cold start delay, consider implementing a scheduled invocation to ensure the instance stays warm and reactive.
- CPU adjustments: In specific cases, you can ask LivePerson to increase the CPU allocation for your function. While this speeds up the startup process, it does not eliminate the cold start completely.
If you use a schedule to keep an instance warm, ensure that your "warming" logic is separated from your regular business logic to avoid unexpected behaviors.
Triggers
Triggers are responsible for invoking your functions. This happens in one of two ways: by raising an event (Event-based) or by calling a specific function directly (Direct invocation).
The following diagram shows the general flow for both invocation styles.
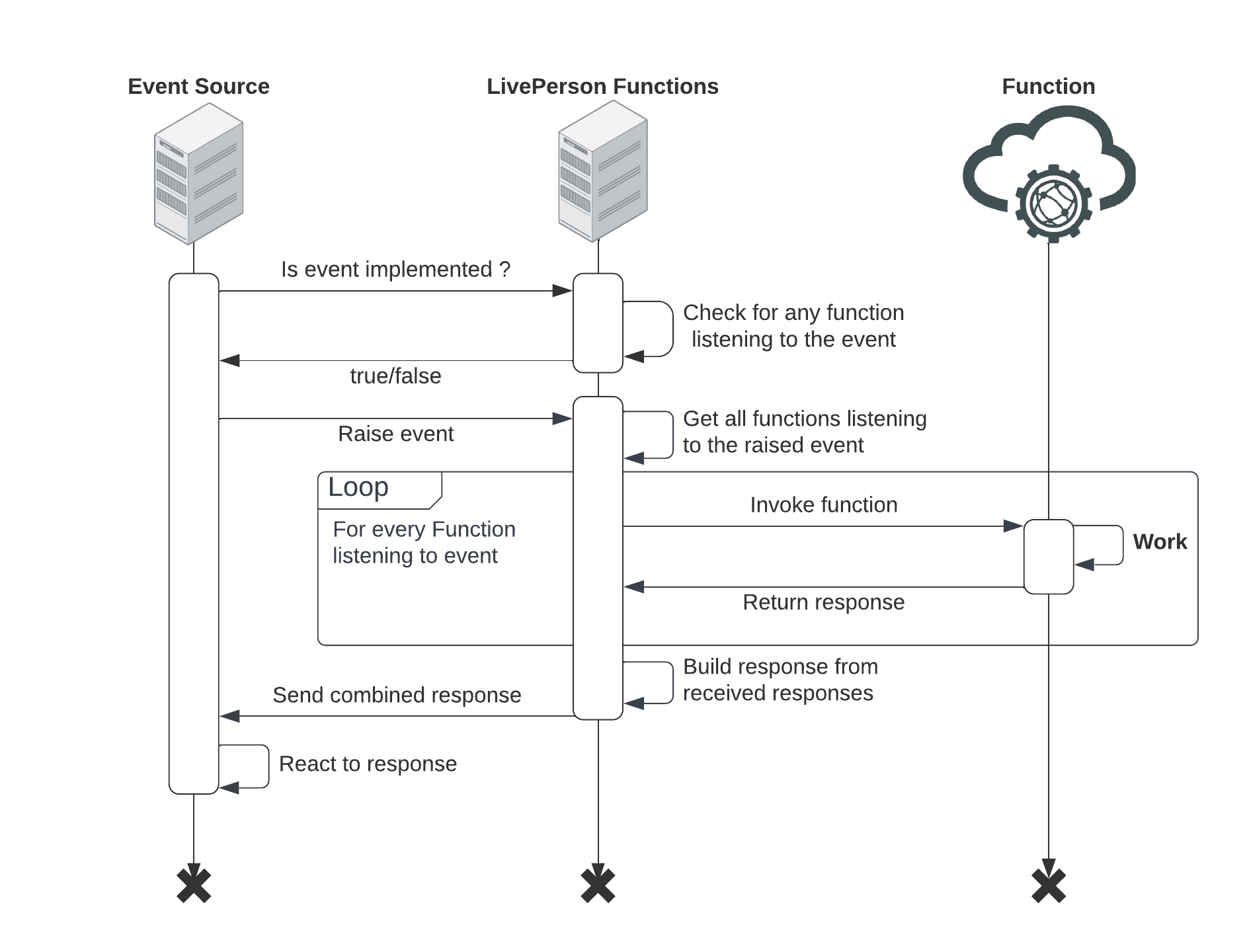
Event-based invocation
In this model, the trigger — usually an Event Source — does not need to know the details of the functions listening to the event.
- The Event Source prepares to raise an event.
- The system checks for productive functions listening to that specific event.
- The trigger raises the event.
- Our platform identifies all listening functions and invokes them.
- Once all responses are received, they are combined and returned to the Event Source.
Please be aware that a failing function will abort the invocation chain for that event.
Direct invocation
Unlike event-based triggers, a direct invocation requires the caller to know the specific UUID of the function they wish to call.
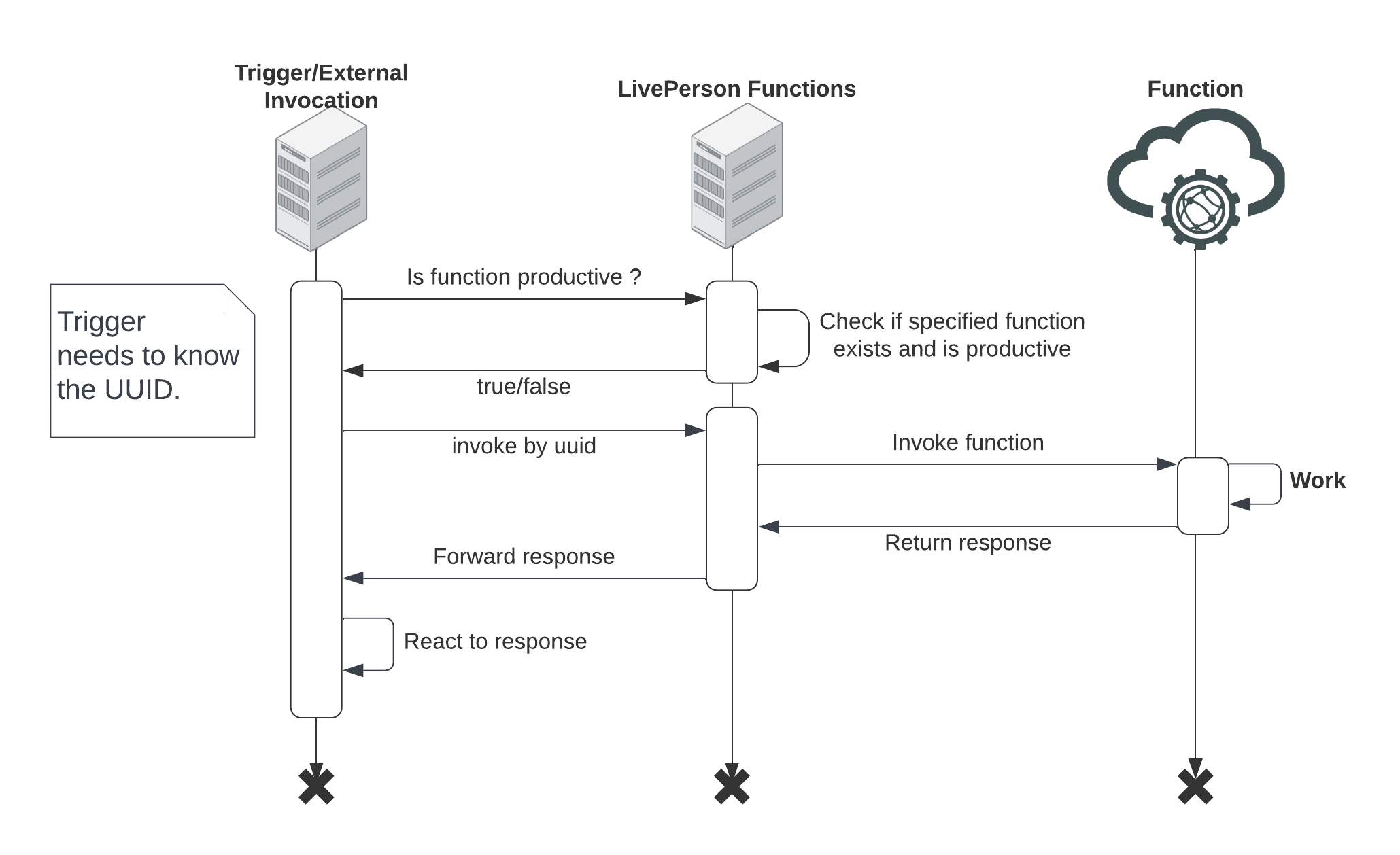
These are typically used by scheduled invocations, external invocations, and select event sources. The caller may check if the function is productive before calling, or they can invoke the function and handle potential "not-found" errors directly. The execution response is sent from the FaaS platform back to the calling trigger.
Execution time(line)
This section highlights the invocation timeline and clarifies which parts count toward our execution time limit of 30 seconds.
As shown in the graphic below, the process begins when a Trigger raises an event. Our services receive this event and begin invoking every function listening to it.
- Event Received: Our service receives the event.
- Processing Starts: The listening function is invoked. The 30s time limit starts ticking down the moment the function instance receives the event.
- Response: Once processing finishes, our service takes over the response and relays it to the triggering service.
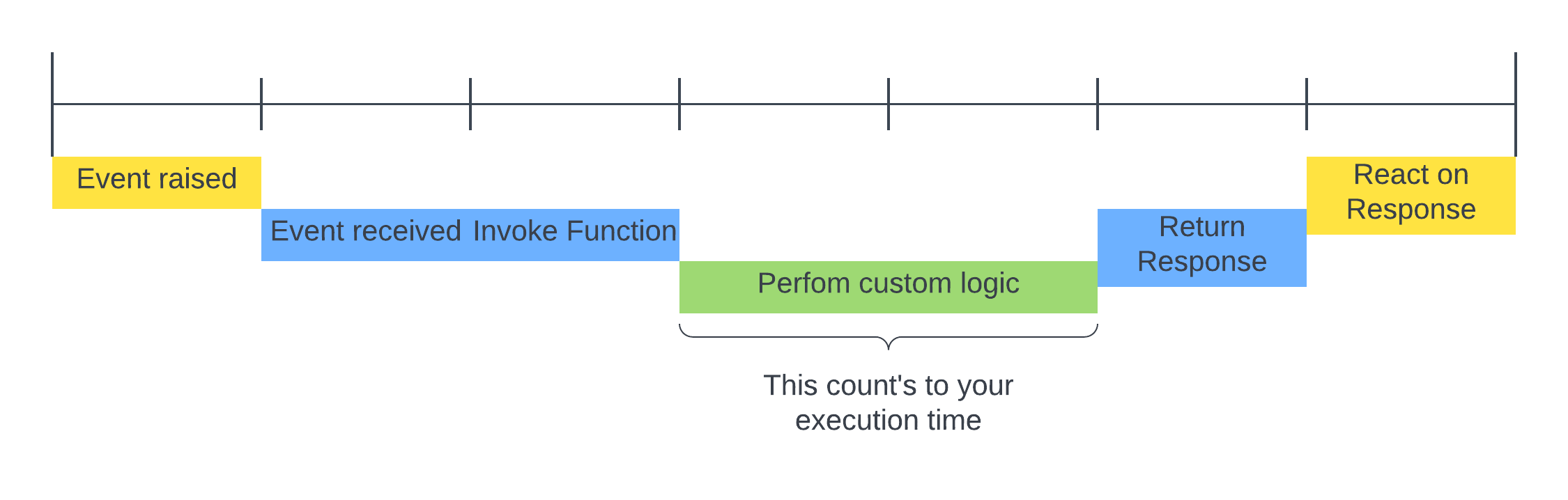
While the Cold Start time does not count toward the 30-second execution limit, it is noticeable in the end-to-end processing time.