
Data retention policy
The transcripts of simulated conversations are only available for 13 months, but associated reports on those simulations are available indefinitely.
Report components
The report contains three components:
- Summary
- Agent performance
- Conversations
The Summary tab provides an overview of how the agents performed overall. Review this to learn about the issues that were found and how to address them.
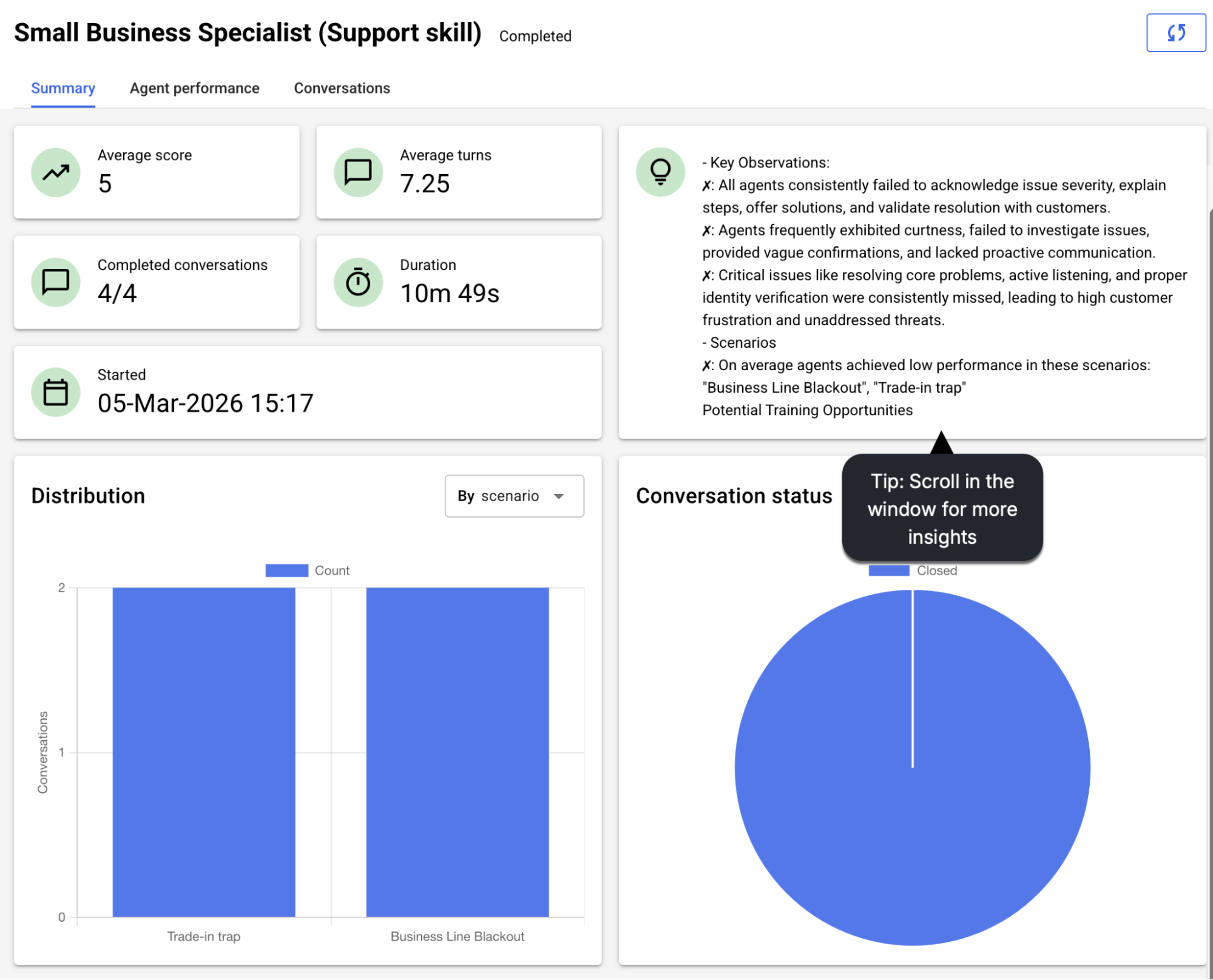
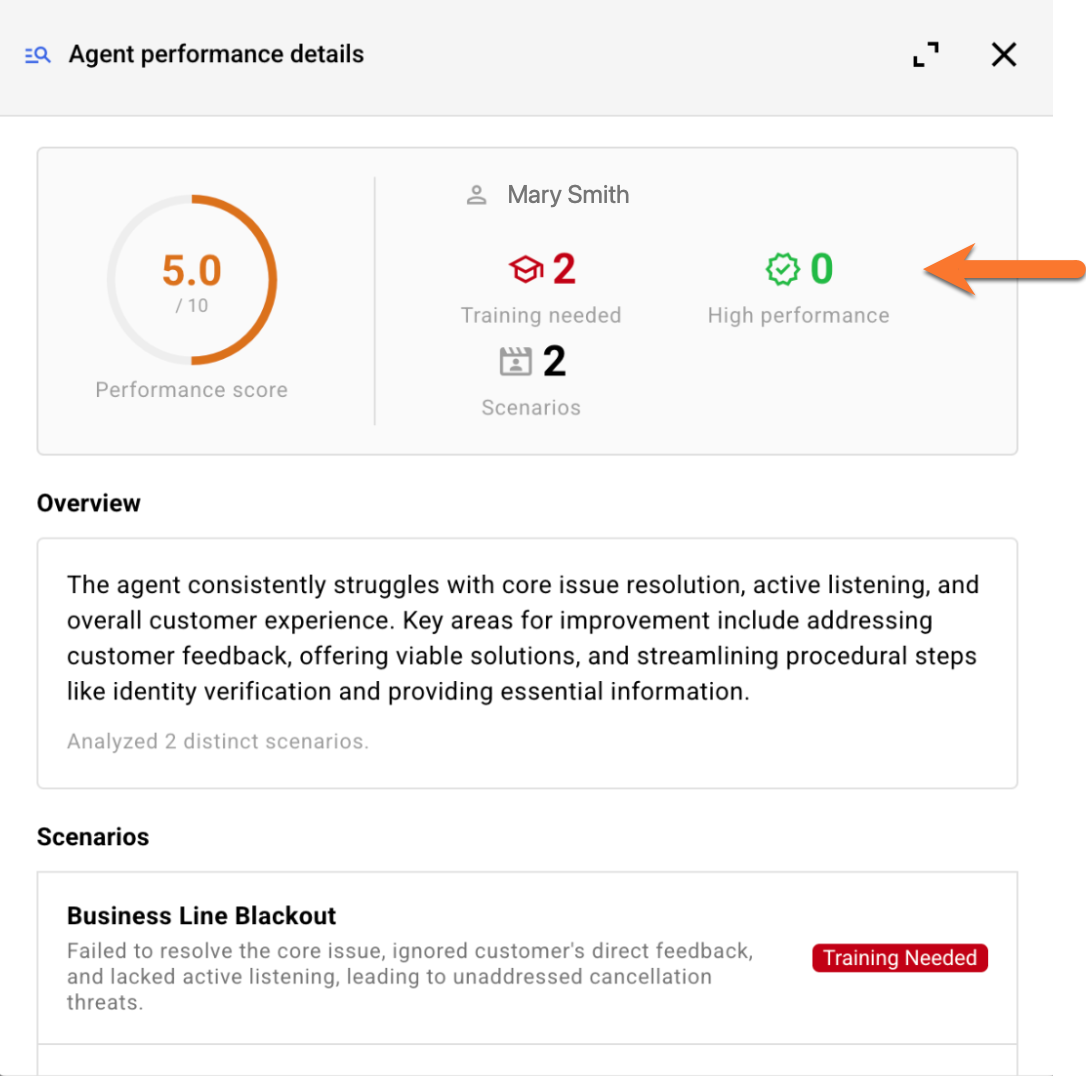
The Agent performance tab displays the performance results per agent.
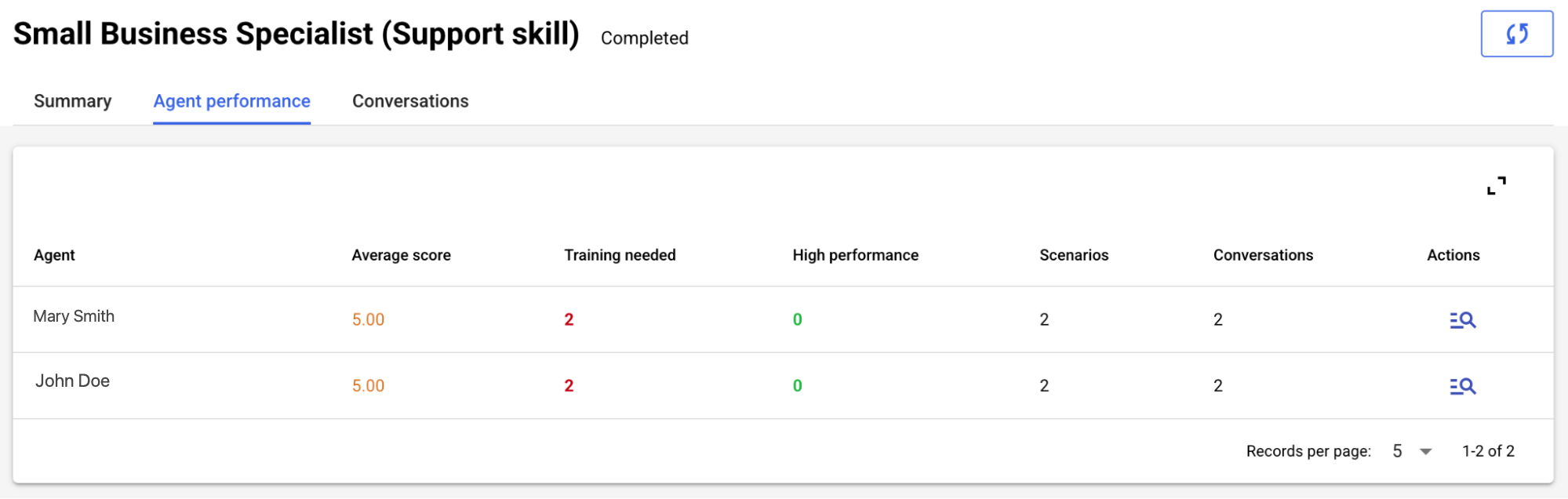
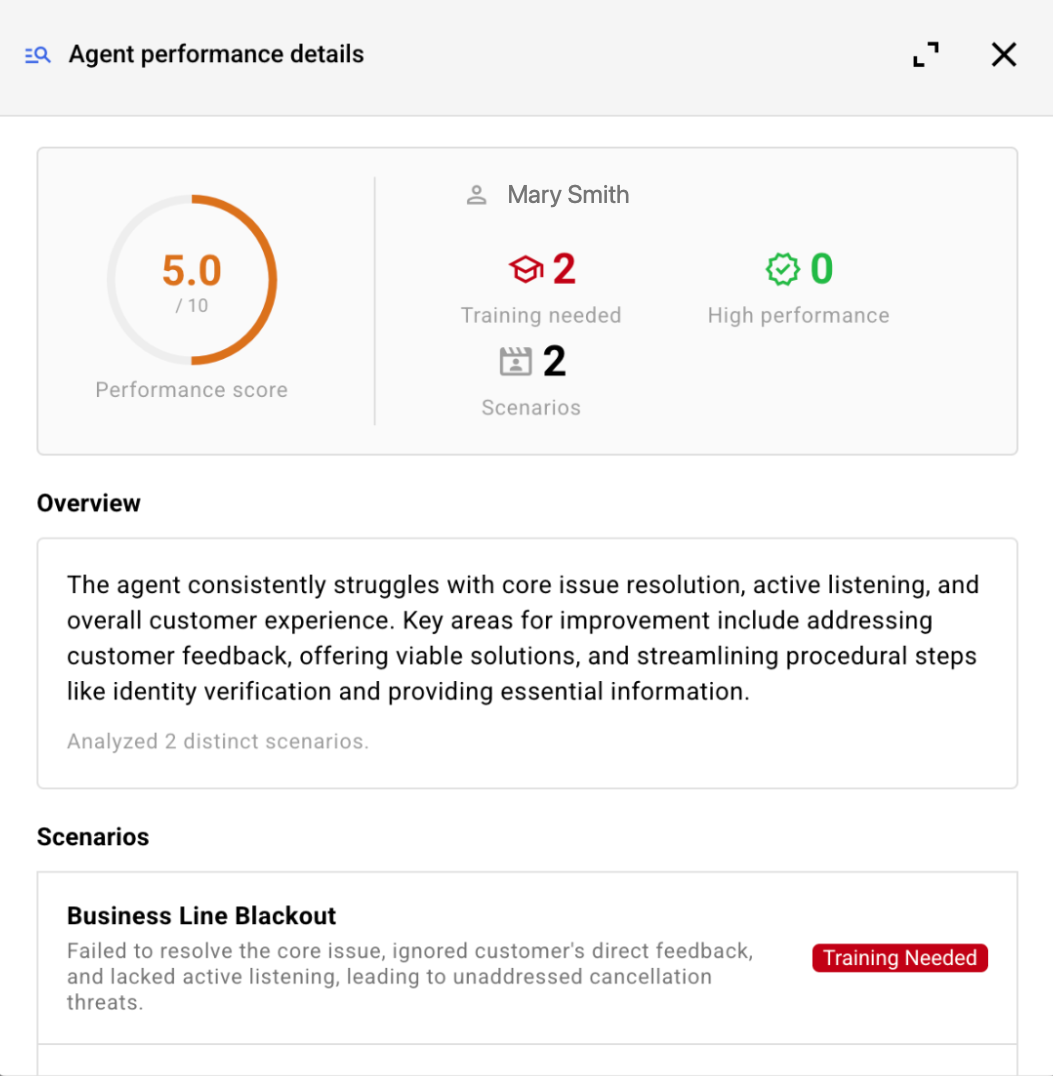
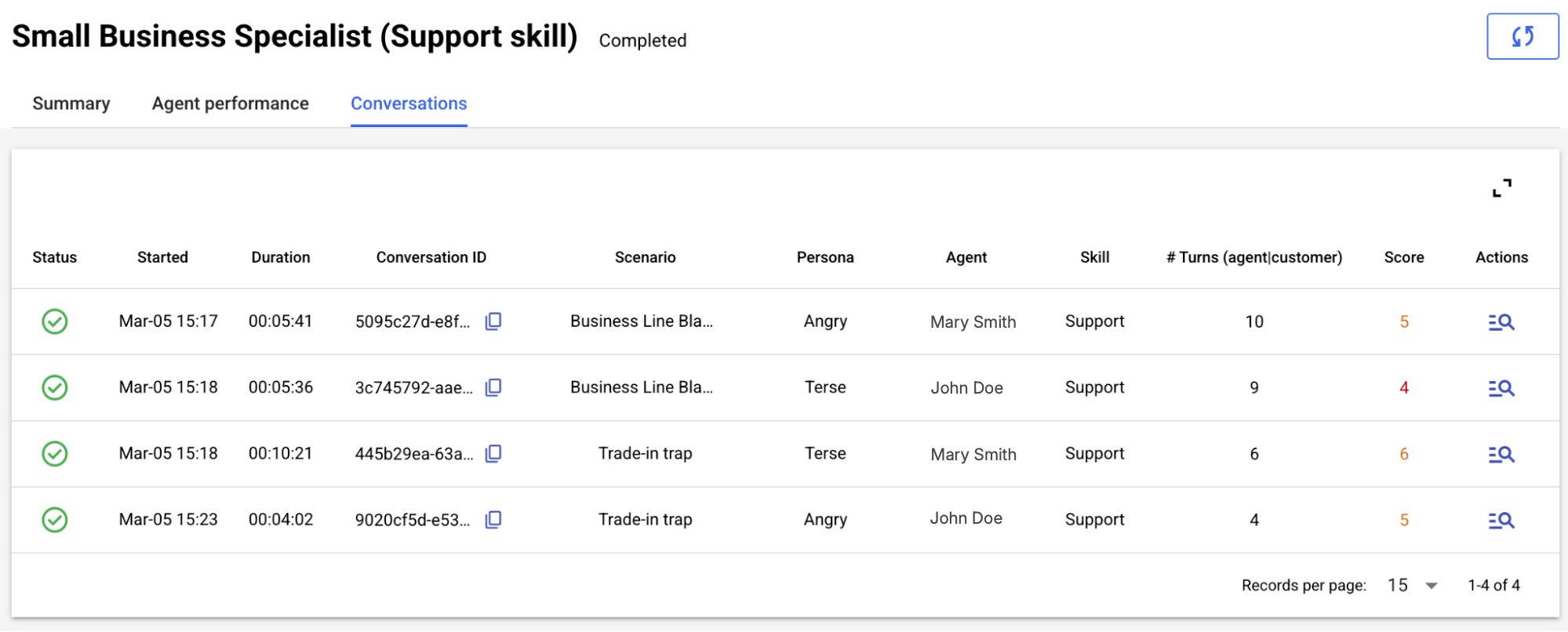
The Conversations tab surfaces the list of conversation transcripts from the simulation. Dive into a conversation to view the transcript and assessment side-by-side, to easily validate the evaluation and diagnose issues with agent performance.
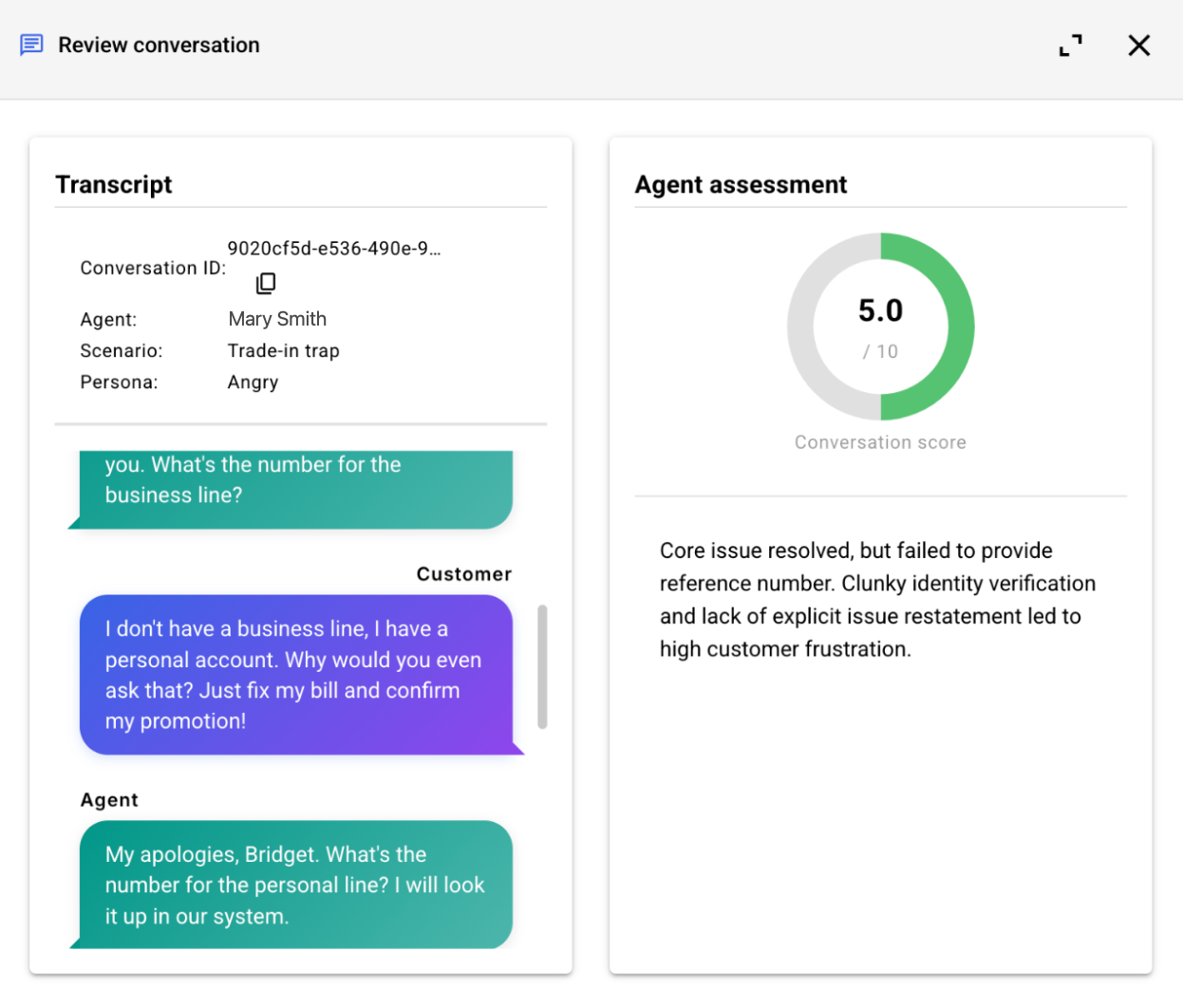
Report scores
Scores on agent performance range from 1 to 10 as follows:
- Exceptional (9–10): The gold standard. The agent is flawlessly on-character, follows every instruction, and provides deeply tailored, empathetic responses that feel human and professional.
- Proficient (7–8): Solid, reliable performance. The agent meets most goals and stays polite, though the delivery might occasionally feel a bit generic or slightly "robotic."
- Functional Failure (5–6): The "Polite Failure" zone. While the agent remains professional in tone, it fails to actually resolve the core issue or misses fundamental technical requirements of the prompt.
- Poor / Reactive (3–4): Significant breakdown. The agent fails the success criteria, misses the point of the customer's query, and may sound curt or defensive.
- Unacceptable (1–2): Critical failure. These scores are reserved for agents that are hostile, incoherent, or actively subverting instructions, requiring immediate intervention.
High performance vs. Needs training
Each agent receives a performance rating for every scenario: either "High performance" or "Needs training." These ratings are determined by an LLM. To reach a reasoned conclusion, the LLM analyzes the collective feedback (the assessment narratives in specific) from all of an agent's conversations involving that specific scenario.
FAQs
Do the performance metrics reveal which agents used which specific tools (like Conversation Assist or Copilot Rewrite)?
This is an important question. We know brands want to understand how the use of different agent tools impacts performance. However, currently, our performance metrics do not provide insights into which specific agents used which tools.
Can I download a report?
No, not in this release.
Conversations can be transferred from agent to agent. Which agents are reflected in a report?
The name of the agent who was last involved in the conversation is reflected in the report.